Современное производство немыслимо
без эффективного управления. Два иностранных слова - маркетинг и менеджмент
- не сходят с уст делового человека. Успех управления во многом определяется
эффективностью принятия интегрированных решений, которые учитывают самые
разносторонние факторы и тенденции динамики их развития.
Важная категория интегрированных
решений - система обработки информации предприятия. Такую систему мы привыкли
называть АСУ - автоматизированная система управления, хотя эта привычка
зашла так далеко, что в каждом конкретном случае стоит уточнять, о чем
идет речь.
Основная цель системы обработки
данных заключается в повышении эффективности работы предприятия.
Система обработки данных
должна:
-
Обеспечивать получение общих или детализированных данных по итогам работы.
-
Позволять легко определять тенденции изменения важнейших показателей.
-
Обеспечивать получение информации, критической по времени, без существенной
задержки.
-
Выполнять точный и полный анализ данных.
Для эффективного решения данных
задач, необходимо включение в процесс создания систем обработки данных
кроме специалистов по АСУ достаточно широкого круга лиц, имеющих отношение
к той информации, которая подлежит анализу и обработке с целью интеграции
общих информационных источников и расширения на основе базы для принятия
решений.
Данный, достаточно краткий
лекционный курс следует рассматривать как введение в системы обработки
данных, как некоторую попытку показать последовательность и возможности
разработки системы обработки данных на основе интегрированных программных
и информационных ресурсов.
Современные информационные
технологии делают бессмысленными бесконечные споры о том, на чем лучше
писать программу, какой формат данных использовать. Вместо организации
переходов “стройными рядами” с одной СУБД на другую, лучше предоставить
каждому специалисту свободу выбора в использовании привычных средств обработки
данных. Наилучшим вариантом в данном случае является использование “открытого
подхода”, который позволяет разработчику использовать широкий диапазон
прикладных программ и технологий для формирования мощных и гибких систем
обработки данных.
В настоящее время наиболее
популярны среди разработчиков такие программные средства, как dBASE IV,
FoxPro, Visual FoxPro, Access и Visual Basic.
-
dBASE и FoxPro - благодаря своей скорости и огромному количеству программистов
во всем мире, использующих различные диалекты xBase.
-
Access - благодаря простоте использования для конечного пользователя и
великолепной устойчивости данных.
-
Visual Basic - благодаря простому языку, который имеет возможность стать
стандартом для настольных приложений и универсальности.
Основная задача данного курса
- дать некоторые базовые представления о методах и средствах создания систем
обработки данных. В качестве базовой выбрана СУБД FoxPro, как наиболее
распространенная в настоящее время.
В соответствии с поставленной
задачей, в рамках данного курса рассматриваются следующие вопросы:
-
Терминология и основные понятия.
-
Постановка задачи и основы теории проектирования баз данных.
-
Модели данных.
-
Основы языка программирования dBASE.
-
Основные операции с базами данных.
-
Разработка практических приложений в среде FoxPro.
-
Основы структурированного языка запросов SQL.
-
Обзор возможностей и особенностей различных СУБД.
Каждому
из нас в повседневной жизни и на работе приходится иметь дело с обработкой
информации. С развитием новых наукоемких технологий возрастает и объем
взаимосвязанных данных, необходимых для решения производственных и чисто
бытовых задач. Взаимосвязанные данные называют информационной
системой. Такая система в первую очередь призвана облегчить труд человека,
но для этого она должна как можно лучше соответствовать очень сложной
модели реального мира.
Ядром
информационной системы являются хранимые в ней данные - факты
реальности, зафиксированные на физических носителях.
-
Информация - совокупность сведений, воспринимаемых
из окружающей среды, выдаваемых в окружающую среду либо сохраняемых внутри
информационной системы.
-
Данные - информация, представленная в виде, позволяющем
автоматизировать ее сбор, хранение и дальнейшую обработку человеком или
информационным средством.
-
Данные - это запись в соответствующем коде наблюдения,
факта, объекта, песни, текста и т.д., пригодная для коммуникации, интерпретации,
передачи, обработки и получения новой информации.
На любом
предприятии данные различных отделов, как правило, пересекаются, то есть
используются в нескольких подразделениях или вообще являются общими. Например,
для целей управления часто нужна информация по всему предприятию. Заказ
комплектующих невозможен без наличия информации о запасах.
Хранящиеся в информационной системе данные должны быть легко доступны в
том виде, в каком они нужны для конкретной производственной деятельности
предприятия.
При
этом не имеет существенного значения способ хранения данных. Сегодня на
предприятии мы можем встретить систему обработки данных традиционного типа,
в которой служащий вручную помещает данные в скоросшиватель, и рядом с
ней - современную систему с применением самой быстродействующей ЭВМ, сложнейшего
оборудования и программного обеспечения. Несмотря на поразительную несхожесть,
обе эти системы должны выполнять одни и те же функции.
Информационные системы обязаны предоставлять достоверную информацию в определенное
время, определенному лицу, в определенном месте и с ограниченными затратами.
Чтобы
понять процесс построения информационной системы, необходимо знать ряд
терминов, которые применяются при описании и представлении данных.
-
База данных - датологическое представление
информационной модели предметной области.
-
База данных - совокупность взаимосвязанных
данных при такой минимальной избыточности, которая допускает их использование
оптимальным образом для одного или нескольких приложений в определенной
предметной области человеческой деятельности.
-
Данные в БД рассматриваются с разных точек зрения.
Это означает, что каждый пользователь работает только с конкретной частью
БД и различные потребители могут применять одни и те же данные.
База данных
является динамической информационной моделью некоторой предметной
области, отображением внешнего мира (объекта,
явления, процесса).
-
Предметная область - часть реальной системы,
представляющая интерес для данного исследования.
-
Предметная область - это отражение в БД совокупности
объектов реального мира с их связями, относящихся к некоторой области знаний
и имеющих практическую ценность для пользователей.
При проектировании
автоматизированных информационных систем предметная область отображается
моделями данных нескольких уровней. Число используемых уровней зависит
от сложности системы, но в любом случае включает логический и физический
уровни. Необходимо различать полную предметную область и организационную
единицу этой предметной области. Организационная единица в свою очередь
может представлять свою предметную область и т.д.
Информация,
необходимая для описания предметной области, зависит от реальной модели
и может включать сведения о людях, местах, предметах, событиях и понятиях.
-
Объект - элемент информационной системы, информацию
о котором мы сохраняем. В реляционной теории баз данных объект называется
сущностью.
Объект
может быть реальным (предмет, человек) и абстрактным (событие, лекционный
курс). каждый объект обладает определенным набором свойств, которые запоминаются
в информационной системе. При обработке данных часто приходится иметь дело
с совокупностью однородных объектов, например таких, как МОДЕЛЬ КОМПЬЮТЕРА.
и записывать информацию об одних и тех же свойствах для каждого из них.
-
Класс объектов - совокупность объектов, обладающих
одинаковым набором свойств.
Таким
образом, для объектов одного класса набор свойств будет одинаков, хотя
значения этих свойств для каждого объекта, конечно, могут быть разными.
Например, класс объектов МОДЕЛЬ КОМПЬЮТЕРА будет иметь одинаковый набор
свойств, описывающих характеристики компьютеров, и каждая модель будет
иметь различные значения этих характеристик.
Каждый объект характеризуется рядом основных атрибутов.
-
Атрибут - это информационное отображение свойств
объекта.
Например,
каждая модель компьютера характеризуется такими параметрами как фирма -
изготовитель, тип процессора, тактовая частота, размер ОЗУ, емкость винчестера,
тип видеокарты, тип мультимедиа, тип CD и т.д. Сотрудники, работающие на
компьютерах, имеют такие атрибуты, как фамилию, имя, отчество, должность
и идентификационный номер.
Каждый
атрибут в модели должен иметь уникальное имя - идентификатор.
Атрибут
при реализации информационной модели на каком-либо носителе информации
часто называют полем данных или просто полем.
-
Поле данных - поименованное элементарное данное.
Взаимосвязь
между перечисленными выше понятиями проиллюстрирована схемой, приведенной
на рис. 1. 1.
-
Таблица - регулярная структура, состоящая
из конечного набора однотипных записей.
Каждая
запись одной таблицы состоит из конечного (и одинакового!) числа полей,
причем конкретное поле каждой записи одной таблицы может содержать данные
только одного типа.
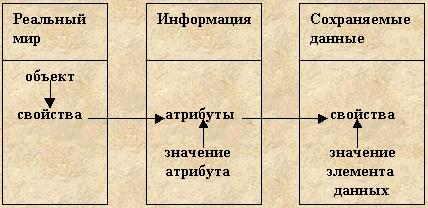
Рис. 1.1. Три области представления данных
-
Запись данных - это совокупность значений
связанных элементов данных, другими словами это поименованная совокупность
полей.
-
Значение данных - действительные данные, содержащиеся
в каждом элементе данных.
Элемент
данных “ФИРМА - ИЗГОТОВИТЕЛЬ” может принимать такие значения, как “АСЕR”,
“АРРLЕ”, “АSТ”, “СОМРАQ”, “СОМРULINK” и т.д. В зависимости от того, как
элементы данных описывают объект, их значения могут быть количественными,
качественными или описательными.
Информацию
о некоторой предметной области можно представить с помощью нескольких объектов,
каждый из которых описывается несколькими элементами данных. Принимаемые
элементами данных значения называются данными.
-
Экземпляр объекта - единичный набор принимаемых элементами
данных значений.
Объекты связываются между
собой определенным образом. Модель объектов с составляющими их элементами
дачных и взаимосвязями называется концептуальной моделью. Концептуальная
модель дает общее представление о потоке данных в предметной области.
Некоторые элементы данных
обладают важным для построения информационной модели свойством. Если известно
значение, которое принимает талой элемент данных объекта, мы можем идентифицировать
значения, которые принимают другие элементы данных этого же объекта. Например,
зная идентификационный номер сотрудника, мы можем выяснить его фамилию,
имя, отчество и должность.
-
Ключевой элемент данных - элемент, по которому можно определить
значения других элементов данных.
Однозначно идентифицировать
объект могут два и более элемента данных. В этом случае их называют “кандидатами”
в ключевые элементы данных. Вопрос о том, какой из кандидатов использовать
для доступа к объекту, решается пользователем или разработчиком системы.
Выбирать ключевые элементы данных следует тщательно, поскольку правильный
выбор способствует созданию достоверной концептуальной модели данных.
-
Первичный ключ - это атрибут (или группа атрибутов), которые единственным
образом идентифицируют каждую строку в таблице.
Понятие первичного ключа
является исключительно важным к связи с понятием целостности баз
данных.
-
Альтернативный ключ - это атрибут (пли группа атрибутов), несовпадающий
с первичным ключом и уникально идентифицирующий экземпляр объекта.
Например, для объекта “сотрудник”,
который имеет атрибуты “ИДЕНТИФИКАЦИОННЫЙ НОМЕР СОТРУДНИКА”, “ФАМИЛИЯ”,
“ИМЯ”, “ОТЧЕСТВО” И “ДОЛЖНОСТЬ”, группа атрибутов “ФАМИЛИЯ”, “ИМЯ”, “ОТЧЕСТВО”
может являться альтернативным ключом по отношению к атрибуту “ИДЕНТИФИКАЦИОННЫЙ
НОМЕР СОТРУДНИКА” (в предположении, что на предприятии не работают полные
тезки).
-
Тип данных - характеризует вид хранящихся данных.
Понятие типа данных в информационной
модели полностью адекватно понятию типа данных в языках программирования.
Обычно в современных СУБД допускается хранение символьных, числовых данных,
битовых строк, специализированных числовых данных (например, суммы в денежных
единицах), а также данных специального формата (дата, время, временной
интервал и пр.). В любом случае при выборе типа данных следует учитывать
возможности той СУБД, с помощью которой будет реализовываться физическая
модель информационной системы.
-
Домен - набор значений элементов данных одного типа, отвечающий
поставленным условиям.
Понятие домена более специфично
для баз данных, хотя и имеет определенные аналогии с подтипами в некоторых
языках программирования. В самом общем виде домен определяется заданием
некоторого базового типа данных, к которому относятся элементы домена,
и произвольного логического выражения, применяемого к элементу типа данных,
который “забраковывает” недопустимые значения. Если вычисление этого логического
выражения дает результат “истина”, то элемент данных является элементом
домена. Например, домен “ФИРМА” (рис. 1.2) определен на базовом типе строк
символов, но в число его значений могут входить только те строки, которые
могут изображать имя (в частности, очевидно, что такие строки не должны
начинаться с какого-нибудь специфичного символа типа знака подчеркивания
или тире). В упрощенном виде понятие домена может характеризоваться как
потенциальное множество допустимых значений одного типа (значением атрибута
“ПОЛ” может быть только либо “мужской”, либо “женский”).
Следует отметить также семантическую
нагрузку понятия домена: данные считаются сравнимыми только в том случае,
когда они относятся к одному домену.
В нашем примере значения
доменов “Код”, “Частота” и “ОЗУ” относятся к типу целых чисел, но не являются
сравнимыми.
ДОМЕНЫ
| Код
Фирма |
Процессор Частота
ОЗУ HDD
Видеокарта Цена |
| Первичный ключ |
Атрибуты |
| Код |
Фирма |
Процессор |
Частота |
ОЗУ |
HDD |
Видеокарта |
Цена |
| 22 |
ACER |
Celeron |
333 |
32 |
4.3 |
32M AGP |
$600 |
| 24 |
ACER |
P II |
400 |
64 |
8.4 |
8M AGP |
$700 |
| 25 |
VIST |
Cyrix |
233 |
32 |
6.4 |
2M |
$470 |
Рис. 1.2. Иерархия понятий в таблице КОМПЬЮТЕРЫ
-
Представление - сохраняемый в базе данных именованный запрос на
выборку данных (из одной или нескольких таблиц).
Результатом выполнения любого
запроса на выборку данных является таблица, и поэтому концептуально можно
относиться к любому представлению как к таблице.
-
Связь - это функциональная зависимость между сущностями.
Если между некоторыми сущностями
существует связь, то факты из одной сущности ссылаются или некоторым образом
связаны с фактами из другой сущности.
Связи могу быть представлены пятью основными характеристиками:
-
тип связи (идентифицирующая, не идентифицирующая, полная/неполная категория,
неспецифическая связь);
-
родительская сущность;
-
дочерняя (зависимая) сущность;
-
мощность связи (cordiality);
-
допустимость пустых (null) значений.
Связь называется
идентифицирующей,
если экземпляр дочерней сущности идентифицируется (однозначно определяется)
через ее связь с родительской сущностью. Атрибуты, составляющие первичный
ключ родительской сущности, при этом входят в первичный ключ дочерней сущности.
Дочерняя сущность при идентифицирующей связи всегда является зависимой.
Связь называется неидентифицирующей,
если экземпляр дочерней сущности идентифицируется иначе, чем через связь
с родительской сущностью. Атрибуты, составляющие первичный ключ родительской
сущности, при этом входят в состав не ключевых атрибутов дочерней сущности.
Мощность связи представляет собой отношение
количества экземпляров родительской сущности к соответствующему количеству
экземпляров дочерней сущности. Для любой связи, кроме неспецифической,
эта связь записывается как i : n.
-
Хранимые процедуры - это приложение (программа), объединяющее запросы
и процедурную логику (операторы присваивания, логического ветвления и т.
д.) и хранящееся в базе данных.
Хранимые процедуры позволяют
содержать вместе с базой данных достаточно сложные программы, выполняющие
большой объем работы без передачи данных по сети и взаимодействия с клиентом.
Как правило, программы, записываемые в хранимых процедурах, связаны с обработкой
данных. Тем самым база данных может представлять собой функционально самостоятельный
уровень приложения, который может взаимодействовать с другими уровнями
для получения запросов или обновления данных.
Правила позволяют вызывать
выполнение заданных действий при изменении или добавлении данных в базу
данных (БД) и тем самым контролировать истинность помещаемых в нее данных.
Обычно действие - это вызов
определенной процедуры или функции. Правила могут ассоциироваться с полем
или записью и, соответственно, срабатывать при изменении данных в конкретном
поле или записи таблицы. Нельзя использовать правила при удалении данных.
В отличие от ограничений,
которые являются лишь средством контроля относительно простых условий корректности
ввода данных, правила позволяют проверять и поддерживать сколь угодно сложные
соотношения между элементами данных в БД.
-
Триггеры - это предварительно определенное действие или последовательность
действий, автоматически осуществляемых при выполнении операций обновления,
добавления или удаления данных.
Триггер является мощным инструментом
контроля за изменением данных в БД, а также помогает программисту автоматизировать
операции, которые должны выполняться в этом случае. Триггер выполняется
после проверки правил обновления данных. Обратите внимание на исключительную
важность в этом определении слова «автоматически». Ни пользователь, ни
приложение не могут активизировать триггер, он выполняется автоматически,
когда пользователь или приложение выполняют с БД определенные действия.
Триггер включает в себя следующие компоненты:
-
Ограничения, для реализации которых собственно и создается триггер.
-
Событие, которое будет характеризовать возникновение ситуации, требующей
проверки ограничений. События чаше всего связаны с изменением состояния
БД (например, добавление записи в какую-либо таблицу), но могут учитываться
и дополнительные условия (например, добавление записи только с отрицательным
значением).
-
Предусмотренное действие выполняется за счет выполнения процедуры или последовательности
процедур, с помощью которых реализуется логика, требуемая для реализации
ограничений.
Использование триггеров при
проектировании БД позволяет получить при разработке приложения следующие
преимущества:
-
Триггеры всегда выполняются при совершении соответствующих действий.
Разработчик продумывает использование триггеров при проектировании БД и
может больше не вспоминать о них при разработке приложения для доступа
к данным. Если для работы с этой же БД вы решите создать новое приложение,
триггеры и там будут отрабатывать заданные ограничения.
-
При необходимости триггеры можно изменять централизованно непосредственно
в БД. Пользовательские программы, использующие данные из этой БД, не потребуют
модернизации.
-
Система обработки данных, использующая триггеры, обладает лучшей переносимостью
в архитектуру клиент-сервер за счет меньшего объема требуемых модификаций.
-
Ссылочная целостность - поддержание непротиворечивости функциональных
зависимостей между сущностями.
Реализация ссылочной целостности
может выполняться как приложением, так и самой СУБД (с помощью механизмов
декларативной ссылочной целостности и триггеров).
-
Ссылочная целостность - это обеспечение соответствия значения внешнего
ключа экземпляра дочерней сущности значениям первичного ключа в родительской
сущности.
Ссылочная целостность может
контролироваться при всех операциях, изменяющих данные. Для каждой связи
на логическом уровне могут быть заданы требования по обработке операций
добавления, обновления или удаления данных для родительской и дочерней
сущности. Могут использоваться следующие варианты обработки этих
событий:
-
отсутствие проверки;
-
проверка допустимости;
-
запрет операции;
-
каскадное выполнение операции обновления или удаления данных сразу в нескольких
связанных таблицах;
-
установка пустого (NULL) значения или заданного значения по умолчанию.
-
Нормализация отношений - это процесс построения оптимальной структуры
таблиц и связей в реляционной БД.
В процессе нормализации элементы
данных группируются в таблицы, представляющие объекты и их взаимосвязи.
Теория нормализации основана на том, что определенный набор таблиц обладает
лучшими свойствами при включении, модификации и удалении данных, чем все
остальные наборы таблиц, с помощью которых могут быть представлены те же
данные.
-
Словарь данных - это централизованное хранилище сведений об
объектах, составляющих их элементах данных, взаимосвязях между объектами,
их источниках, значениях, использовании и форматах представления.
